Scott’s Bass Lessons and BassBuzz on YouTube. I’m learning how to play bass guitar 🎸 now. So far, these two channels were the most helpful with both the practice lessons, and the inspiration to move forward.
Event-driven architecture done right (Tim Berglung, Devoxx Poland 2021). Try to learn what you’re trying to do, before you elaborate the architecture, if uncertainty is very high, and you don’t know exactly what businesses are asking. Just start with something (architecturally) simple.
Acquired’s lessons learned from 200 company stories: optimism always wins (Sony); nothing can stop the will to survive (Nvidia); it’s never too late (TSMC); focus on what makes your beer taste better (Amazon and all utility companies); don’t be talent — own the business (Oprah, Tail Swift); you’ll get the partners you ask for (Amazon’s “If you’re not on my bus, get off”), and more.
Go 1.19beta1. As usual, lots of good improvements in the language’s runtime and the compiler, with one particularly interesting addition being the new “knob” runtime/debug.SetMemoryLimit.
Queries in PostgreSQL: 4. Index scan (Postgres Pro). An in-depth overview of how PostgreSQL decides if it will use an index.
One particular thing I had no idea about before I read the article was that “The Index Scan cost is highly dependent on the correlation between the physical order of the tuples on disk and the order in which the access method returns the IDs”. That explains several cases from my own experience, where postgres kept using “unexpected” sequential scans, after we added “another index” to the database.
Digital object identifier (DOI) (Wikipedia). A DOI is a persistent identifier or handle used to identify various objects uniquely. It aims to be “resolvable”, usually to some form of access to the information object to which the DOI refers. This is achieved by binding the DOI to metadata about the object, such as a URL. Thus, by being actionable and interoperable, a DOI differs from identifiers such as ISBNs, which aim only to identify their referents uniquely.
Platforms and Power (Acquired). “7 Powers” author Hamilton Helmer and Chenyi Shi (Strategy Capital), joined Acquired Podcast to discuss platform businesses, and how the “Power” framework applies to them.
Halfthings (Mat Ryer).
Building something for the users to play with, to touch, to feel, to break, makes all the difference and moves the conversations away from the meta.
Doing “one thing” or “building an MVP” can easily pull you into a “too much” for a validation phase. Build a “halfthing” instead.
Rethinking Classical Concurrency Patterns (Slides), Bryan C. Mills, GopherCon 2018. Brian demos the implementation of typical concurrency patterns, following the famous Go proverb: “Don’t communicate by sharing memory; share memory by communicating.”
GoLab Keynote, Bill Kennedy, GoLab 2018. Bill demoes the ways to reason about the performance of a Go application, with the help of Go runtime tracer.
The Scheduler Saga, Kavya Joshi, GopherCon 2018. Kavya shows what stands behind the magic of Go runtime.
Understanding Channels, Kavya Joshi, GopherCon 2017. Kavya explains how channels work under the hood.
Keeping the list here, in public, should help my future self, in a situation where I’m stuck with a mind-blocker, and I need to quickly pull out a piece of community wisdom from the backyards of my memory. The list isn’t meant to be complete, and I expect to add more links here, moving forward.
Did I miss any? Share your suggestions with me on Twitter.
Everything I list below are the steps I found relevant, after I’ve self-tested positive for COVID in Berlin, in the end of January 2022.
Friday, 28th January 2022
I woke up with some mild symptoms of cold. On the day before I worked from home, and only had a usual an hour-long walk around Prenzlauer Berg — Mitte after the workday. The rapid antigen test (Schnelltest) was negative.
While still working from home, I took a “quiet Friday” at work, to simply focused on some mundane routines.
I went for a short walk in the afternoon, bought some grocery, and headed home.
Saturday, 29th January
Didn’t feel anywhere better or worse: mostly had a runny nose and a dry throat. I didn’t want to wait in the line for a quick-test, so I’ve just walked around the city for an hour and went home.
Sunday, 30th January
It felt the same as it’d been the day before, although the dry throat started to feel a bit more intense. Walked around for an hour, came home, made some coffee ;)
A couple hours later I started to cough. I made a self-test — we still had some at home — and,
When Go code propagates an error, the following pattern is very popular:
fmt.Errorf("failed to find a parking slot: %w", err)
// Or
fmt.Errorf("could not call mom: %w", err)
These “could not”, “failed to”, “unable to” make sense when my mind is in the local context of the function, method or package. But, in most of the cases I have to deal with, it makes the resulting log message overloaded with informational garbage:
unable to ask about the cat: failed to call mom: failed to do request: Get https://: context canceled
While discussing this issue with a colleague, we came up with the following “better” strategy:
only the logger should express its attitude to the facts, using words “error”, “failed”, etc
the business code must operate only with facts, e.g. “call mom”.
My definition of “good coffee places” includes, although, by no mean limited by, offering a “not too fruity” filter coffee, batch brew, or a decent americano.
One particularly confusing type of the resource for me was cpu. For example, in the manifest above, the my-app container declares a request for “100m” of the CPU. What does that mean?
Many years ago I embraced “tabless” development workflow: I use buffers, when I’m in Vim; I also switch tabs off in both Goland and VS Code, as the first thing after I install the IDEs to a new laptop.
I’m trying the same with Firefox web-browser now:
Enable toolkit.legacyUserProfileCustomizations.stylesheets switch in Firefox’s config (via about:config page or inside user.js).
Place the styles below into %PROFILE%/chrome/userChrome.css (I pick the actual path to the profile directory from Firefox’s about:support page).
// Hide the tabs.
// Beware that hidding the tabs with "display: none" will ruine you browser's recent history,
// I've learned that in a hard way ;)
#TabsToolbar > .toolbar-items {
opacity: 0;
pointer-events: none;
}
// Pull the navigation bar up, on top of the empty space, that left after we'd hidden the tabs.
#nav-bar {
margin-top: calc((7px + var(--tab-min-height)) * -1);
}
// On macOS, when not in full screen, shift the urlbar's panel to the right,
// after close-minimise-expand buttons.
:root:not([inFullscreen]) #nav-bar-customization-target {
margin-left: 65px;
}
(Optional) In Firefox’s “General” preferences, switch off “Ctrl+Tab circles through tabs”. With that, pressing Ctrl+Tab exposes all currently open pages (similar to how on macOS or other OS one switches between the opened applications with ⌘+Tab).
Overall I’m fairly happy with how it ended up. Although, some things aren’t quite ideal yet (might add more as I use this setup):
I wish there was a shortkey to enter a “modal mode”, where I could filter the list of open pages, to search for a particular page, and to switch to this page. Something similar to :ls command in Vim, or ⌘+E in Goland. I can use Firefox’s “Search amongst Tabs” for that (press ⌘+L to focus into the URL bar, and querying with “%[space]”) but that requires some getting used to.
Firefox has “Show all tabs” button (Ctrl+Shift+Tab) but the way it works, at least in Firefox 91, is very confusing and random. It seems to me, its behaviour is tightly coupled to the browser’s Tab UI.
Update (2022-12-16) I’ve found Panorama Tab Groups extension, which exposes the opened pages, and it works pretty well for me. One very minor thing is that I have to use Cmd+Shift+E because Cmd+E is locked in Firefox.
At least for now, my homelab cluster (4x Raspberry Pi, k3s, etc) is available only for the devices on my local network, inside a custom DNS zone k8s.pi.home. I don’t think there are practical reasons to run anything with HTTPS in that setup, but there are cases, like browser extensions, where it’s required.
Turned out, in 2021, it’s fairly straight forward to set up a Certificate Authority (CA), that will issue TLS certificates to “secure” the ingress resources. At least, it’s way simpler comparing to how I remember it was back in the days. All thanks to cert-manager and some YAML.
First thing is to install cert-manager to the cluster. k3s comes with helm-controller, that gives us a way to manage helm charts with Custom Resource Definitions (CRD). The following manifest defines a new namespace, and a resource of a kind HelmChart, to install cert-manager inside this namespace:
And now, I can use selfsigned-issuer to issue TLS certificates for the ingress resources (Traefik ingress in the k3s’s case). E.g. to play around, I run an open-source version of LanguageTool server. The ingress manifests for the server looks like as following:
Of course, any certificate signed by my CA won’t be automatically trusted by anyone, including my own system. If I try to access https://languagetool.k8s.pi.home, any HTTP client will raise a “failed to verify the legitimacy of the server” issue. I don’t know if there is a better way to solve that, but I can hack that around by installing the cluster’s root CA certificate into the system’s keychain, and telling the system, that it should “trust” the certificate:
$ kubectl get secret/selfsigned-ca-root-secret -o json \
| jq -r '.data["ca.crt"]' \
| base64 -D > ~/tmp/selfsigned-root-ca.crt
$ open ~/tmp/selfsigned-root-ca.crt
Choose “Always trust” the certificate in the keychain’s certificate settings. The server looks legitimate now!
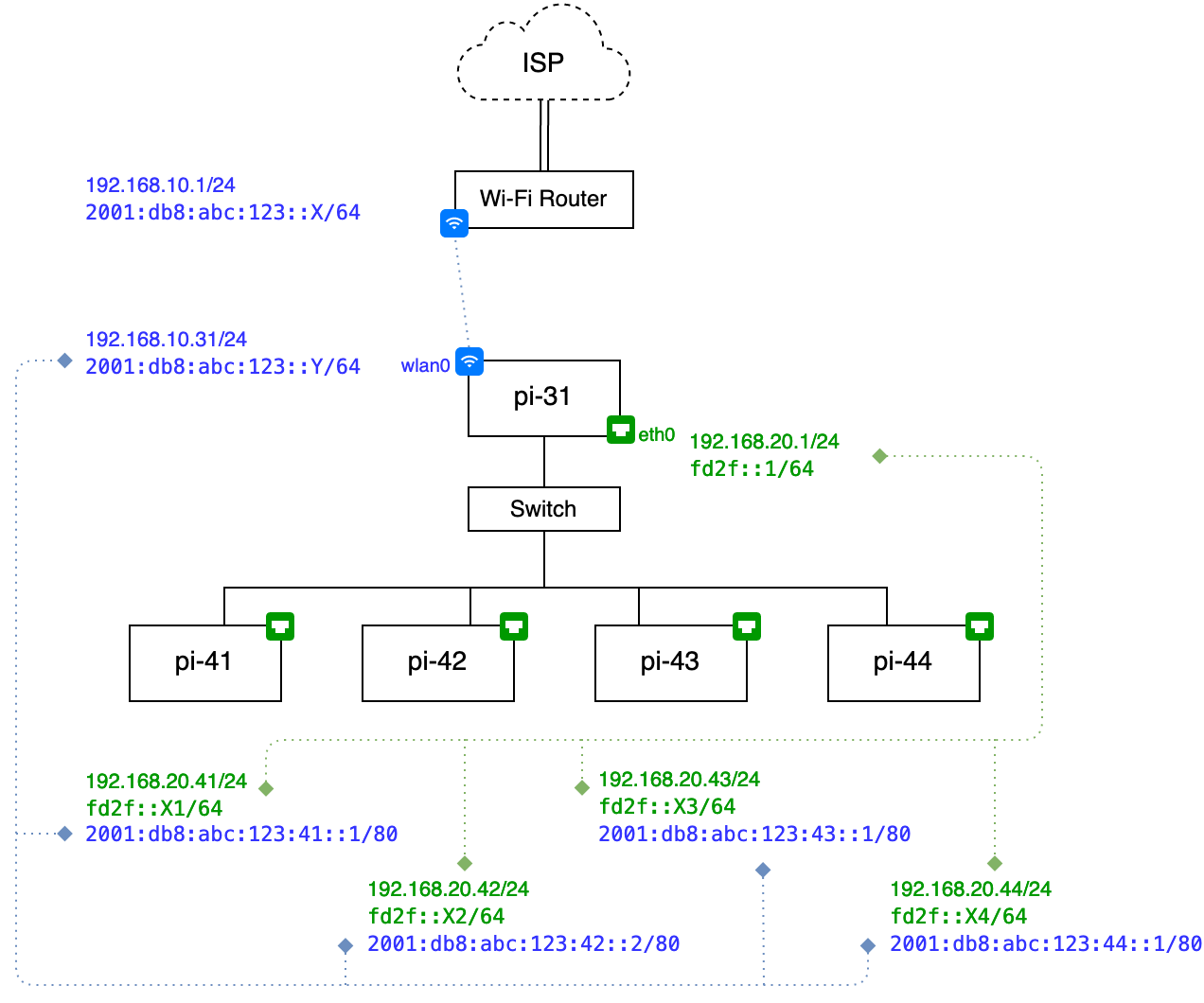
Initially, when I assembled a homelab cluster of Raspberry Pis, everything was directly connected to my Wi-Fi router with the Ethernet cables. This worked fine but this “stack of boards” behind the sofa in the centre of our small flat bugged me a bit.
Last year I decided to reorganise the cluster, turning it into a wireless-to-wired island, which I could relocate anywhere within the flat, without doing any special cable management, while staying cheap and avoid stacking the appartment with even more gadgets. After going through a number of trials and errors, the final setup looks as the following:
Different colours contour the connections between two logical subnets — more on that later. Here what we have on the schema (top to bottom):